How I Implemented Chat with PDF Feature using Atlas Vector Search and RAG Architecture?
Sachin Dapkara, Sun, Mar 10 2024
Topics/Technologies Discussed: Amazon S3, Celery, Redis Pub/Sub, PyMuPDF, Text Embedding, Cosine Similarity, Celery Signals, Atlas Vector Search, RAG Architecture
It's my first blog, so forgive me for mistakes if any :)
In this blog, we're gonna talk about how I implemented the chat-with-pdf feature in one of my ongoing project (group-project) i.e. EduHub-AI (opens in a new tab).
I'll segregate my implementation into two parts for better explanation:
- Create Post Endpoint & Processing the Files
- Chat with PDF
Create Post Endpoint & Processing the Files
Uploading Files to Amazon S3
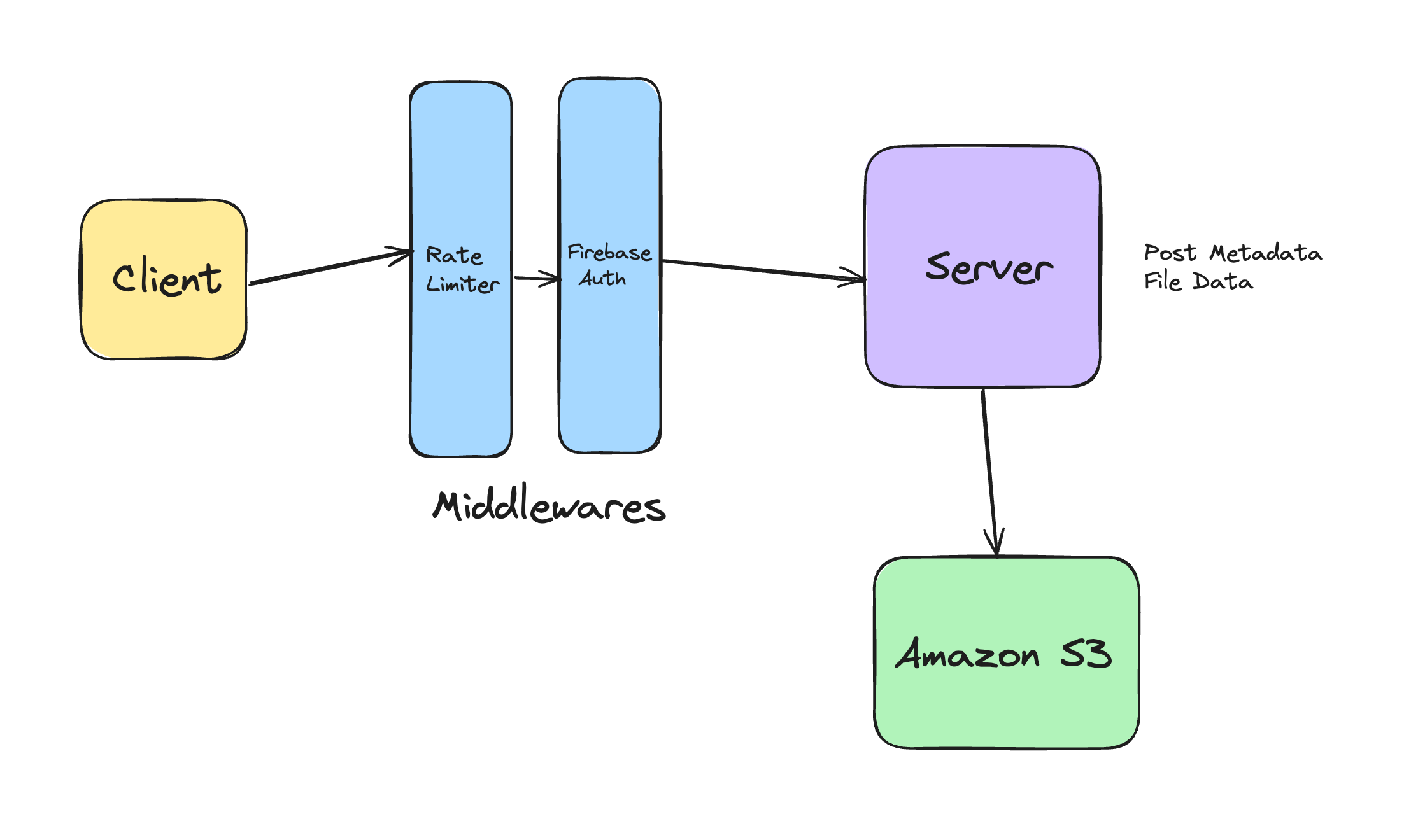
When this endpoint is hitted with a request, the meta-data about the post is retrieved using request.form. Then we validate the input data using marshmallow (opens in a new tab).
After this we get the files sent by the client through the request object. So now we have the post meta-data (eg. type, title, description, topic), and the files to be uploaded.
To store the files for a specific post, I'm using the Amazon S3 (opens in a new tab). It is a cloud-based object storage service offered by Amazon Web Services (AWS).
Now for each file, I'm reading its data, and putting that data to the S3 bucket in a proper structured folder structure. Once I have uploaded a particular file to the S3 bucket, I have its URL to access it.
Processing Files Asynchronously with Celery and Redis Pub/Sub
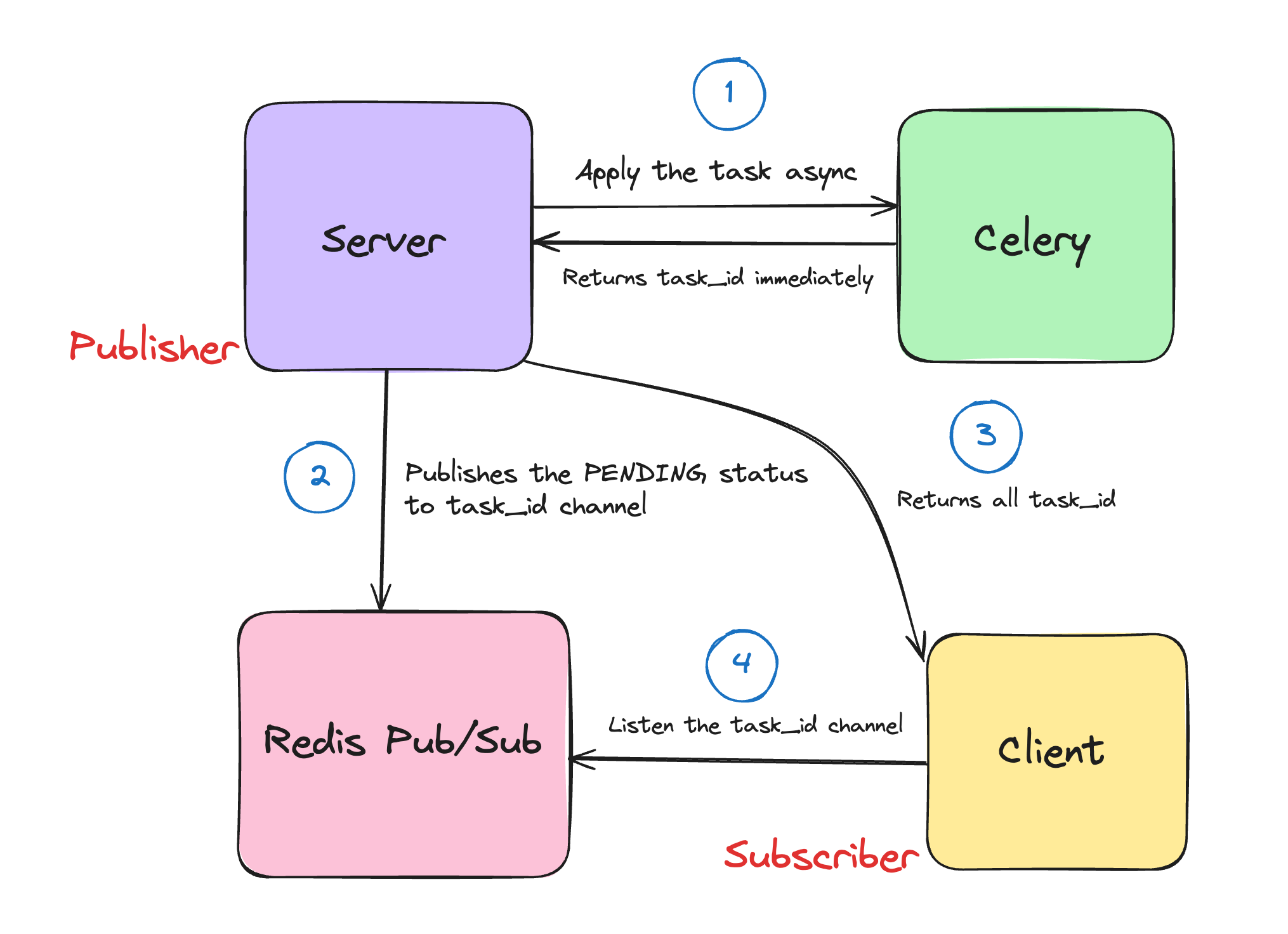
This is the most important stage of the whole process as you have to process the file to extract the text content from the file, and other things as well that we'll be discussing in the next section. But this can't be done on the current request-response cycle as this process takes a significant amount of time, and increases load on the server.
Celery
So for the processing task, I'm using Celery (opens in a new tab).
Celery is a powerful distributed task queue framework for Python that is used to handle asynchronous and scheduled tasks in web applications and distributed systems.
Redis Pub/Sub
So for each file, I'm getting a task id from Celery, then treating those task ids as individual channel, I'm publishing the current task status (PENDING) for each task. So here I'm using Redis Pub/Sub (opens in a new tab).
Redis Pub/Sub involves sending messages from a publisher i.e. server in our case to a Redis channel (task_id), which is then received by one or more subscribers who are listening to that channel i.e. client.
But how will client know about on which channel to subscribe to? As we have the task_ids we will complete this request-response cycle by returing the task_ids to the client, and this way the client can subscribe to those task_ids and receive the task status SUCCESS/FAILURE.
Process Uploaded File Celery Task
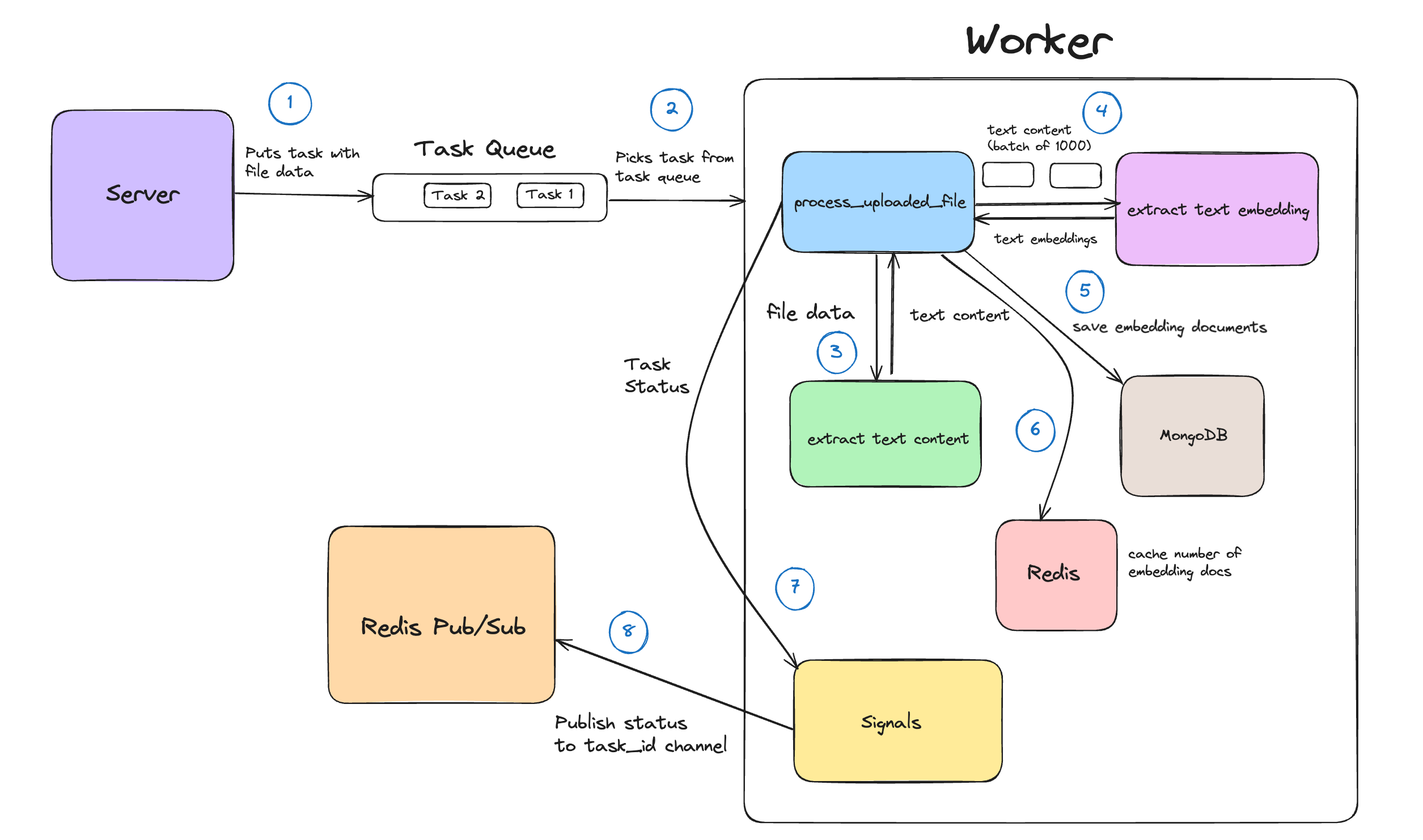
So I have created a Celery task that processes the uploaded files. Now what's the role of this task?
Text Content Extraction (PyMuPDF)
This task first extracts all the text from the file, in our case a PDF. To extract the text content from the PDF, I've used PyMuPDF (opens in a new tab). After this I calculate the total length of the extracted text content i.e. number of characters.
Text Embedding
Next thing to be done is to get the text embeddings of the extracted text. I have used Gemini's embedding-001 (opens in a new tab) model to extract the text embeddings from the given input text. You must be thinking what is a text embedding and what's the role of it in this?
Text Embedding is a technique used to represent text data in a continuous, high-dimensional vector space. It captures semantic meaning and context of words, sentences, or documents, enabling advanced natural language processing tasks. In our usecase, it's necessary to compare user's queries with the content of a particular PDF document. It facilitates efficient search and retrieval by transforming both the user input and PDF text content into a common embedding space, enabling accurate matching and relevant results.
Also to remember I'm doing batching here, means that I'm processing the text content into multiple batches each consisting of 1000 characters for efficient memory utilization and avoding overloading the system. Also it takes care of the input token limit (2048 tokens) of our used model.
Saving Embedding Documents to MongoDB
Once we're done with getting the text embeddings, I'm saving them to the embedding collection inside the MongoDB. There are two important fields inside each embedding document which are text_content and its corresponding embeddings.
To perform Atlas Vector Search (opens in a new tab) I've created a search index on the embeddings path. Its numDimensions are 768 which is the output token limit of the embedding model. In simple words it's the size of the vector returned by the embedding model. The similarity is going to be cosine.
Cosine Similarity
Cosine similarity is a measure of similarity between two vectors in a multi-dimensional space. In our case, the user input query and the PDF text content. It calculates the cosine of the angle between the vectors, indicating their alignment in direction. A value of 1 implies perfect similarity, 0 implies no similarity, and -1 implies perfect dissimilarity.
Error Handling
I'm also caching the number of embedding documents saved for a particular PDF file. It'll be utilized in the next stage. For caching purposes, I'm using Redis (opens in a new tab).
This way, the processing task for a particular file is done. But you must be thinking what if an error comes for any reason? What will happen in that case?
I have applied the retry policy on this particular task i.e. process_uploaded_file. So that in case of failure, the workers will try processing it for maximum three retries.
Celery Signals
Do you remember that we had published a PENDING message to our task_id channels, but when those tasks are completed or failed due to some reason, how to publish their status to their respective channels?
Here, Celery Signals (opens in a new tab) comes to the rescue.
Celery Signals are events triggered during task execution. We're using two signals, one for
successand another forfailure. Thesuccesssignal is emitted when a task completes successfully whereas thefailuresignal is emitted when a task encounters an error or exception. So in case of both signals we'll publish theSUCCESS/FAILUREmessage respectively to that particular task_id channel.
Chat with PDF
We're done with the first stage i.e. "Create Post Endpoint & Processing the Files". It's the feature time i.e. "Chat with PDF". Two words that I'll emphasis the most in this stage are already mentioned in the title of this blog. Yes, I'm talking about Atlas Vector Search and RAG Architecture. So let's go through them quickly.
Atlas Vector Search
Atlas Vector Search is a feature offered by MongoDB Atlas, the fully managed cloud database service provided by MongoDB. It enables users to perform similarity searches on vector data stored in their MongoDB databases. This feature leverages advanced machine learning algorithms to index and search high-dimensional vector data efficiently.
RAG Architecture
The RAG (Retrieve, Aggregate, Generate) architecture is a framework used in NLP for text generation tasks. It consists of three main stages:
-
Retrieve: In this stage, relevant information is retrieved from a knowledge source such as database in our case (embedding collection). We'll be using Atlas Vector Search for the same.
-
Aggregate: In this stage, the retrieved information is then aggregated and processed to distill key insights. This could involve summarization techniques.
-
Generate: Finally, based on the aggregated information, the system generates the desired text output. In our case, we'll be using a text generation model (
gemini-pro) to produce coherent and contextually relevant text that addresses the given query.
Chat with PDF Process
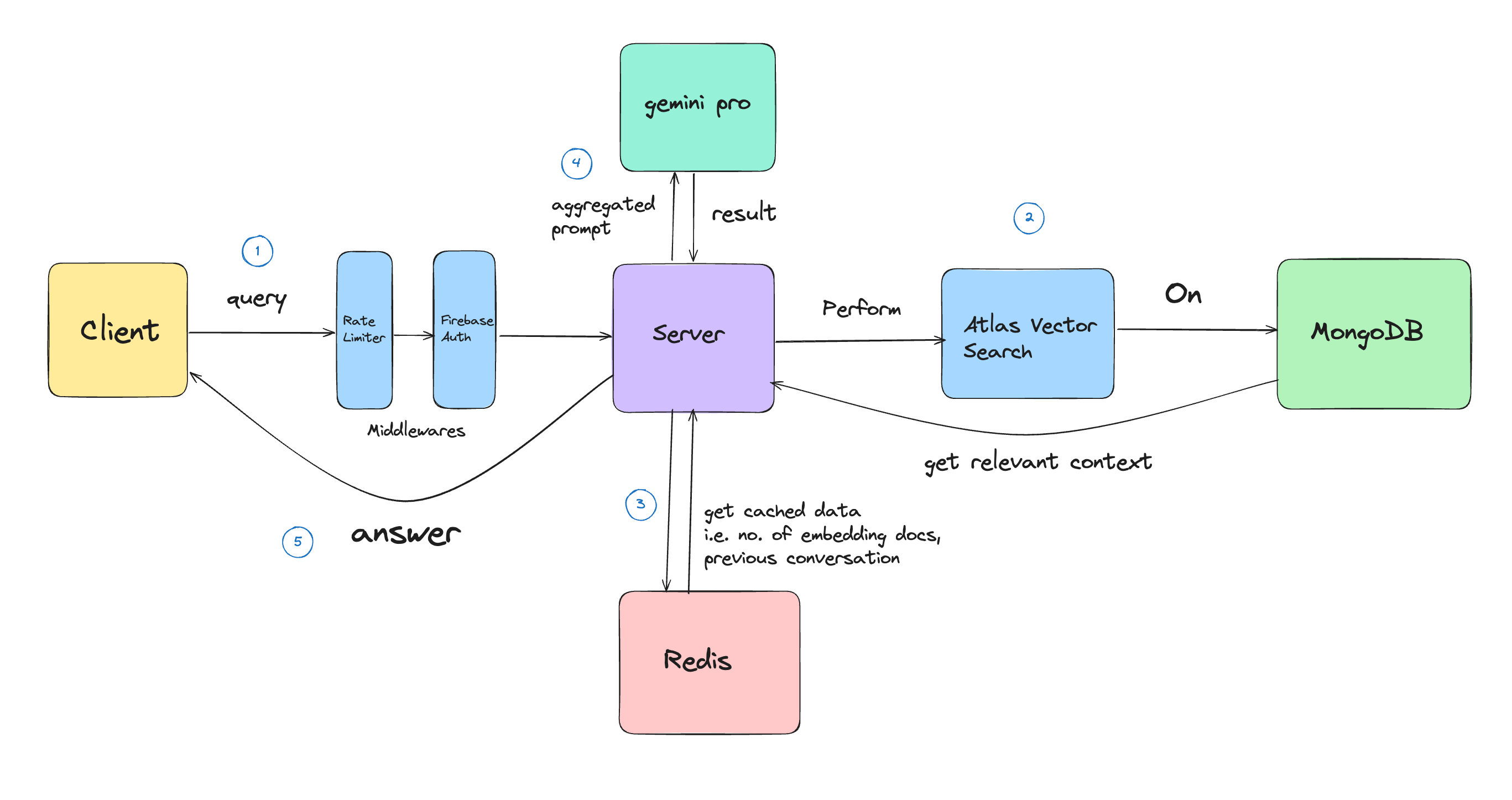
As we're done understanding about both of them, let's proceed to the whole process.
When client hits the endpoint, we validate the input data and get the query asked by the user. For this query, we extract the text embedding using the same model we used for extracting for PDF text content.
Then we retrieve the cached data for this particular attachment_id means pdf_id in simple words. It includes "number_of_embedding_documents", and "previous_conversation" (if any).
Retrieve Stage
Now, it's time to perform the vector search on the embedding collection. For this we create an aggregation pipeline. This is how it looks like:
results = Embedding.objects.aggregate(
[
{
"$vectorSearch": {
"index": "embeddedVectorIndex",
"path": "embeddings",
"queryVector": query_embeddings,
"filter": {"attachment_id": str(attachment_id)},
"numCandidates": number_of_embeddings,
"limit": limit_results,
}
},
{
"$project": {
"_id": 0,
"text_content": 1,
}
},
]
)Let's go through each of the fields in the vectorSearch.
-
index: Specifies the name of the index where the vector embeddings are stored. You have to give a specific name to your vector search index while creating it.
-
path: Defines the field within documents where vector embeddings are stored.
-
queryVector: Represents the vector embedding of the query input.
-
filter: Allows filtering results based on additional criteria to narrow down search scope.
-
numCandidates: Determines the number of candidate embeddings to consider during the search process, optimizing efficieny by limiting the pool of potential matches.
-
limit: Specifies the maximum number of results to return from the search.
In the aggregation pipeline, the number_of_embeddings is equal to the cached number of embedding documents for that particular PDF, and the limit is equal to the ceiled square root of number_of_embeddings. This way, we can get the retrieve the relevant context related to the input query.
Aggregate Stage
Now comes the "Aggregate" stage. I haven't performed any summarization techniques. I'm directly defining the prompt to be given to the LLM (gemini-pro).
prompt = f"""
Instruction: Please provide an informative response to the following question with the help of your knowledge, the Retrieved Context and the Previous Conversation in Markdown format.
Question: {query}
Retrieved Context: {retrieved_context}
Previous Conversation: {previous_conversation}
Note: If the model is unable to generate an answer based on the retrieved context or previous conversation, please follow these instructions:
1. Notify the user that the generated answer is based on the model's own knowledge.
2. Provide an answer using the model's own knowledge.
3. If possible, prompt something related to the topic to continue the conversation.
"""Here query is the input query asked by the user, retrived_context is the context that we retrived in the "Retrieve" stage, and previous_conversation is the cached previous conversation messages between the model and the user. Though I have defined limits on the length of previous conversation to be included in the prompt to keep the context relevant.
Generate Stage
Finally, comes the last stage i.e. "Generate" in which use the gemini-pro model to generate the text content from the given prompt. Once we have got the results, we concatanate the current query and results to the previous_conversation and cache it for future uses (TTL - 1 day).
This way we complete this request-resonse cycle and returns the answer to the user.
Thank you for reading it. Hope you liked it :)